


Hey Everyone, The context and backstory for this blog is that I wanted to get into Kubernetes security, and after exploring various open-source tools and projects, I realized that eBPF is the basics that you need to know if you want to get into this
There are many resources available for learning eBPF, which I will be listing down, but I felt the need to write this one because, as a complete beginner to eBPF, I had many questions that I thought were not covered altogether in a blog and also to map all my learning.
Observability:
https://www.youtube.com/watch?v=fAvzodP4lbA: Itay Shakury This is a cool video that will help you understand how eBPF helps in observability.
Sangam Biradar 's blog on eBPF for cybersecurity
https://blog.cloudnativefolks.org/ebpf-for-cybersecurity-part-1
https://blog.cloudnativefolks.org/ebpf-for-cybersecurity-part-2
Anais Urlichs 's blog and video on eBPF:
First, let's highlight the buzzwords and phrases that you will see in each blog and that, in my opinion, gave me a better understanding of what eBPF is.
"eBPF does to Linux what JavaScript does to HTML."
Now how do we relate eBPF to Linux and JavaScript to HTML?
We know that HTML is used to write and design web pages, and to make them interactive, we use Javascript to make them user-friendly, which brings in different additional features such as various events on certain activities such as clicking a button, So how do we relate this to eBPF and Linux?
eBPF (extended Berkeley Packet Filter) is a technology that allows users to write and execute custom programs in the kernel space of a Linux-based operating system. These programs can be used for a variety of purposes, such as monitoring and modifying network traffic, tracing system calls, and implementing security policies.
What are kernel space and user space?
User space is where user applications run, and kernel space is where the operating system runs.
When talking about increasing the capabilities of Linux, there are two possible ways that you may think:
As Linux is open source, you would think to make changes to the Linux kernel, but this would bring many other problems. Making changes directly in the Linux kernel would open up many possibilities for threats, and it would certainly be difficult to maintain the code, bring in new changes, and deploy it to users as many people use Linux systems.
Another option that you may consider is kernel modules. This one may work, but there are issues, such as the fact that it would be easy to do something wrong, so there is a need to do this in a sandboxed environment within the Linux kernel.
Compatibility: Kernel modules are dependent on the kernel version and can cause compatibility issues if the kernel version changes. This makes it difficult to maintain and update the eBPF program.
Performance: Kernel modules incur a performance penalty due to the overhead of switching between user space and kernel space. In contrast, eBPF programs can run entirely in the kernel space and therefore have better performance.
Security: Kernel modules have full access to the kernel and can potentially introduce security vulnerabilities or instability. In contrast, eBPF programs run in a restricted environment and are subject to strict security policies.
A few terms that you would come across while learning eBPF
Berkeley Packet Filter (BPF) is a technology that allows for low-level packet filtering and analysis in the kernel space of an operating system. It was originally developed for the BSD operating system and has been adapted and extended for use in Linux.
Bytecode: Bytecode is a type of code that is designed to be executed by a virtual machine. It is a low-level representation of a program that is optimized for efficient execution on a specific platform.
Hook points: Hook points are specific locations in the kernel where code can be injected to intercept and modify events. In the context of BPF, hook points are used to execute BPF programs at various stages of packet processing, system calls, and other kernel events. This is similar to pre-commit hooks in git.

The eBPF workflow involves several steps:
Writing an eBPF program: The user writes an eBPF program using a programming language such as C or Python. The program is compiled into eBPF bytecode using the BPF Compiler Collection (BCC).

In most of the scenarios, eBPF is not directly used, but instead, Cilium, bcc, or bpftrace are used, which provide an abstraction on top of eBPF and do not require writing programs directly but instead offer the ability to specify intent-based definitions, which are then implemented with eBPF.
Loading the eBPF program: The eBPF program is loaded into the kernel space using the eBPF Program Loader.
Executing the eBPF program: The eBPF program is executed in response to an event, such as a system call or a network packet. The eBPF program runs in a sandboxed environment, where it can access and modify data using eBPF maps.
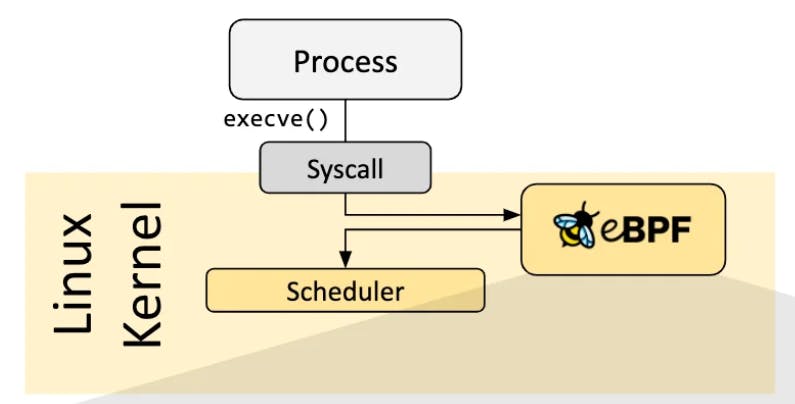
Sharing data with user-space applications: The eBPF program can share data with user-space applications using eBPF maps. This allows user-space applications to monitor and analyze kernel events in real time.
Loading via hooks
When the desired hook has been identified, the eBPF program can be loaded into the Linux kernel using the bpf system call. This is typically done using one of the available eBPF libraries.
As the program is loaded into the Linux kernel, it passes through two steps before being attached to the requested hook.
eBPF follows a Loader and Verification Architecture; whenever a hook is achieved, the eBPF program is loaded and executed through system calls, which are done through eBPF libraries. As discussed above, loading can be done through hooks, and as for verifiers,
Verification
From what we have learned so far, there are two major problems that we can have, and these are problems solved through eBPF architecture.
The first would be security issues. As this is executed in the Linux kernel, we have to make sure that it does not crash the system, turn forever into a loop, and never exit this loop.
Also, this program (eBPF) should have enough privileges to run in the environment.
To solve this issue, a verifier is used. This ensures that the program is safe to use and does not cause the above problems.
Compilation (JIT: Just in Time Compiler)
The Just-in-Time Compiler translates bytecode to machine-specific instructions for efficiency and performance. This can make it appear as if the code was compiled natively into kernel code or executed as Linux modules.
How does eBPF solve the problem of security in kernel space that would pop up due to our additional code?
Sandboxing: eBPF programs are executed in a sandboxed environment, which limits their access to sensitive data and system resources. This prevents malicious or poorly written eBPF programs from causing damage to the system.
It uses a JIT (Just In Time Compiler) and a verification engine that compiles and verifies eBPF bytecode at runtime, ensuring that it is safe to execute and does not violate any security policies. This process includes validating the eBPF program's memory accesses, verifying its type safety, and checking for buffer overflows and other common security vulnerabilities.
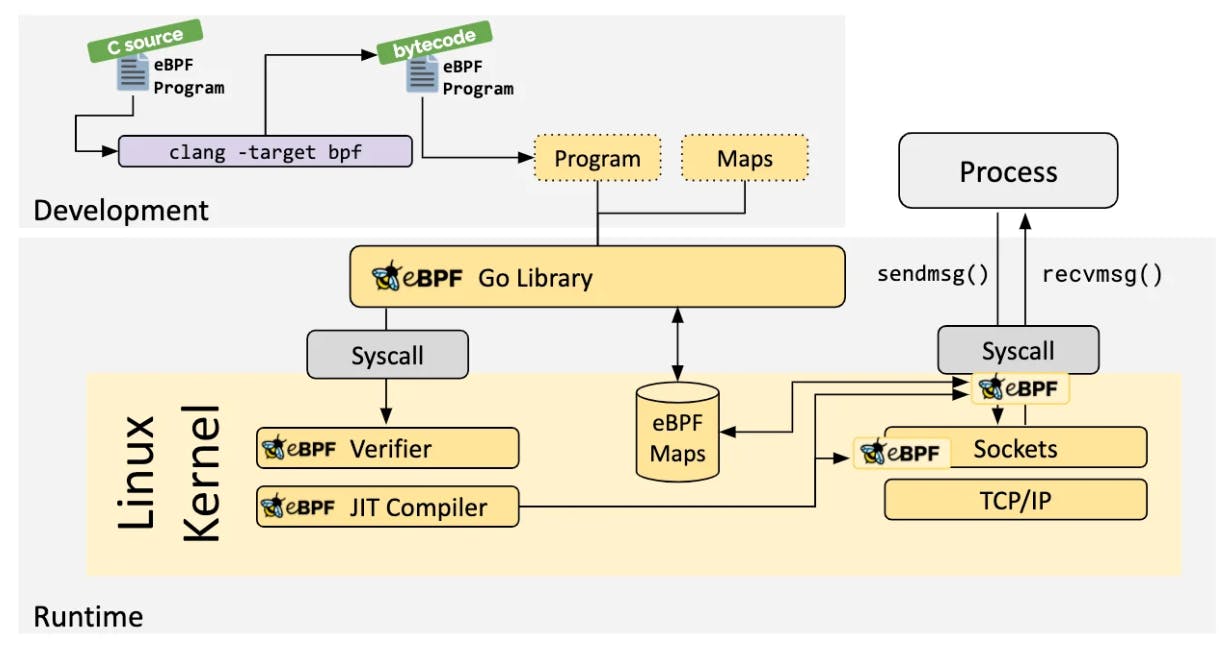
This resolves our problem of writing and adding code without worrying about the security, compatibility, or performance of the system.
I believe this is a good start to learning eBPF. See you in the next article.😁😁